Much like the human brain learns through patterns and associations, neural networks are designed to recognize structure in data, especially in language. This computational linguistics project applies machine learning to the task of authorship attribution, training a model to predict the poet or songwriter behind individual lines of text. Through examining stylistic patterns across 40 different authors, this project explores how computational methods can capture the nuances of creative linguistic expression.
LANGUAGE
Python
TOOLS
Google Colab
DURATION
7 weeks
TASK
In this project, I trained a text classification model to predict the author of individual lines of poetry or song lyrics from a given data set. The core challenge was to teach a model to recognize the stylistic nuances in each line-without any broader context-and use that information to make accurate predictions on unseen lines in a separate test set.
More specifically, I modified and trained a Long Short-Term Memory (LSTM) neural network to handle this classification task. The LSTM processed each line as a sequence of words, learning how language patterns vary across different writers.
GETTING STARTED
My professor, Dr. Eric Rosen, tasked each student in our class to select a poet or songwriter and contribute ten pieces of their work to two shared files: trainfile.json and testfile.json. Nine of these works were added to the trainfile.json file for training purposes, while the tenth was reserved for testfile.json to be used for testing.
The trainfile.json file contains a structured list of song lyrics or poetic lines from multiple tracks and artists. Each entry is formatted as a two-element list: the first element is either a line of lyrics or a song title, and the second element is the name of the artist or author. Song titles are distinguished from regular lyric lines by being enclosed in quotation marks and preceded by a backslash (e.g., ["\"Halo\"", "Beyonce"]), making them easily identifiable. (View below)
The testfile.json is formatted in the same way, consisting of a list of lists, where each inner list includes a lyric or title string and the corresponding artist.
Starter Code
Below is the starter code provided by my professor. The first code block defines a simple neural network model using PyTorch that can predict the author of a line of poetry or song lyrics. It works by first converting each word in the line into a numerical format the model can understand, using what's called word embeddings. As the model reads the line word by word, it updates its internal memory using either a standard Recurrent Neural Network (RNN) or a more advanced Long Short-Term Memory (LSTM) system, depending on the setting. This memory helps the model keep track of context as it processes the line. Once it has read the entire line, it uses what it has learned to make a final prediction about which author most likely wrote it. The model was designed to be flexible and lightweight, making it a practical example of how natural language processing and machine learning can be used to analyze text patterns and infer authorship.
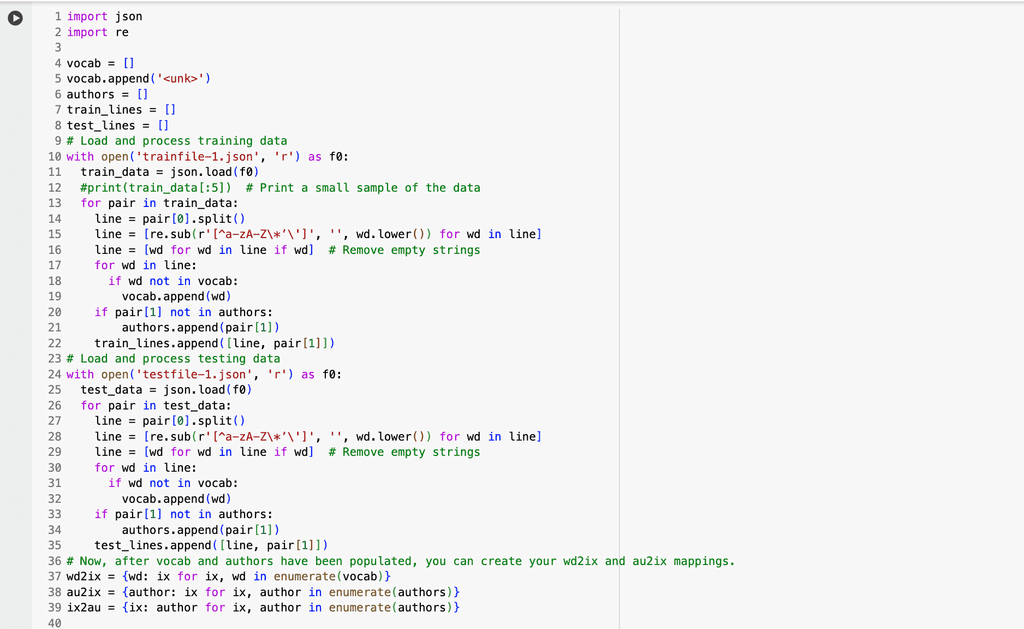
The second code block loads and prepares the training and testing data needed to train a machine learning model that predicts the author of a line of poetry or lyrics. It starts by importing two modules: one for handling JSON data and another for working with text patterns. It then creates lists to store the vocabulary (words the model will learn), author names, and the processed lines of text from both training and test datasets. The training and test files are read from JSON files, where each entry contains a line of text and its corresponding author. For each line, the code splits it into individual words, cleans them by removing punctuation or symbols, and converts them to lowercase. It adds any new words to the vocabulary and any new authors to the author list. Each cleaned line, along with its author, is saved for later use in training and evaluation. After processing all the data, the code creates dictionaries to map each word and each author to a unique number. These mappings are crucial because machine learning models work with numbers, not raw text. This preprocessing step sets the foundation for the model to understand and learn from the data.

My Code
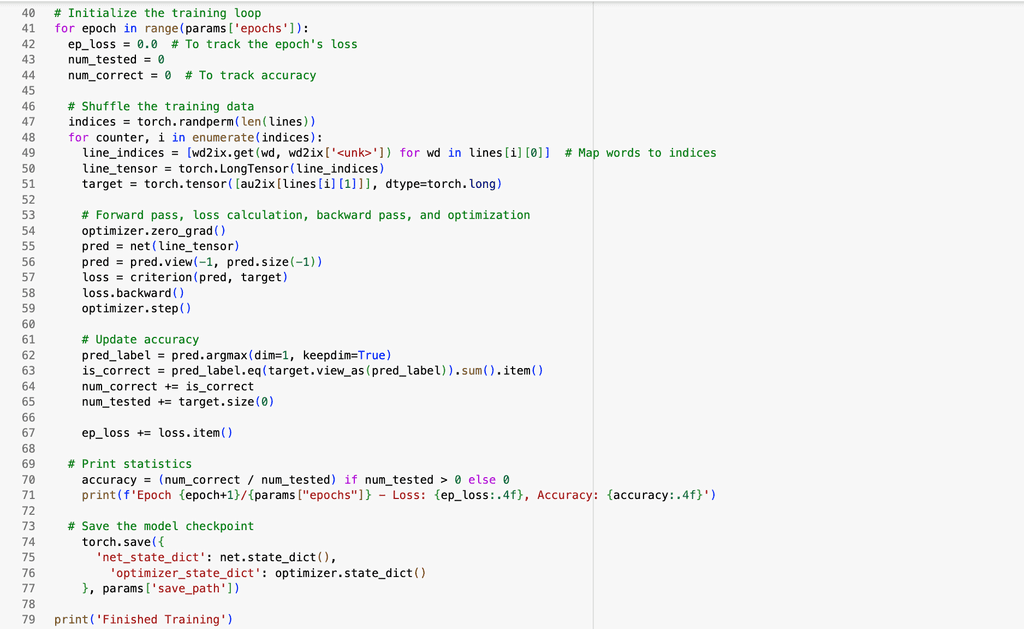
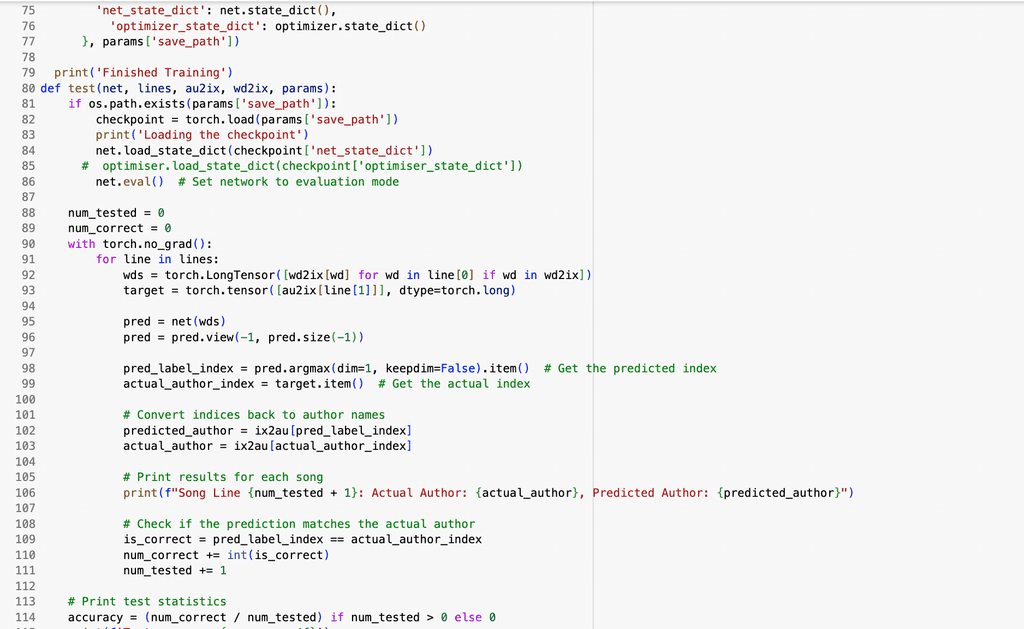
This code below trains and evaluates the neural network that predicts the author of a line of poetry or lyrics based on the words in the line. It begins by converting each unique word and each author in the dataset into numerical indices, which are essential for feeding text data into a neural network. The model parameters set LSTM to true. The training function starts by attempting to load any previously saved model checkpoints, allowing it to resume from where it left off rather than starting from scratch each time. It then processes each line in the training dataset by converting the words into their corresponding indices, running the sequence through the model to predict an author, comparing that prediction to the true author label, and adjusting the model’s parameters to reduce errors. This loop runs over one epoch (an epoch is a complete pass through the dataset), tracking both loss and accuracy to monitor learning progress. At the end of each epoch, the model is saved so that the best-performing version can be reused later. The testing function reloads the trained model and evaluates its performance on unseen examples. For each test line, it outputs both the predicted author and the correct author, and calculates the overall prediction accuracy. This setup allows the model to learn and distinguish stylistic patterns in writing, giving it the ability to attribute authorship based solely on stylistic characteristics found in text.

RESULTS
I chose to implement an LSTM (Long Short-Term Memory) model rather than a standard RNN. LSTMs are designed to better capture long-term dependencies in sequential data, which is particularly important when working with song lyrics or poetry lines that can vary significantly in length. Their specialized memory cells allow them to retain context over longer sequences, making them a strong fit for this task of authorship prediction based on text.
To evaluate model performance, I calculated accuracy by comparing the model's predicted authors to the actual authors of individual lines. This can be seen in the third code block , where the model outputs a prediction for each input line and compares it to the true label. Accuracy is then computed as the ratio of correct predictions to the total number of predictions made.
During training, the model reached approximately 40% accuracy, which already suggested it was struggling to confidently distinguish between authors. When tested on unseen data, performance dropped substantially (to around 4%), indicating either overfitting or a significant difference between the training and test datasets. This performance gap suggests that while the model may have memorized certain patterns during training, but it failed to generalize effectively to new examples.
One interesting outcome I had hoped for was to see the model confuse lines written by Beyoncé and Solange. As sisters and fellow artists, their lyrics sometimes explore similar themes, and I was curious to see if the model would pick up on those subtle overlaps in style or subject matter. However, this wasn’t the case. Instead, the model appeared to associate similarities more strongly between artists like Charlie Puth and Harry Styles—likely due to shared characteristics such as age, genre, or stylistic tendencies in their songwriting. Although the model’s accuracy was limited, these insights show its potential to uncover stylistic links and point toward future opportunities to refine model performance through data augmentation or model tuning.
CONCLUSION
This project demonstrates how machine learning can be applied to natural language tasks and showcases the intersection of data science, linguistics, and creative expression. By modifying and training an LSTM model to predict the author of a given song or poetry line, I explored how neural networks can detect subtle stylistic patterns in language that might not be immediately obvious to the human eye. While the model’s performance leaves room for much improvement, this project reflects my ability to take an abstract problem, translate it into a structured data science pipeline, and generate meaningful insights (even with imperfect predictions). It also highlights my interest in leveraging technical tools to answer creative questions, a skill set I’m excited to bring into real-world!